
Quand un incident n’est pas juste un incident
En cybersécurité, on observe souvent une confusion entre les notions d’évènement, d’incident et de crise. Pourtant, ces trois termes correspondent à des niveaux d’impact et de gravité bien distincts, qui nécessitent chacun une réponse adaptée.
Un évènement est simplement une action détectée sur un système d’information : il s’agit d’un signal, d’un comportement ou d’un message qui pourrait indiquer un problème de sécurité, mais sans impact avéré. Un évènement peut être bénin, comme une tentative de connexion échouée ou une alerte générée par un antivirus.
Un incident, en revanche, est un ou plusieurs évènements qui ont réellement compromis la sécurité d’un système d’information. Cela peut toucher la confidentialité, l’intégrité ou la disponibilité des données ou des services. Un incident nécessite une investigation rapide et des mesures correctives immédiates.
La crise représente le niveau le plus élevé : c’est un incident majeur, souvent complexe, multi-systèmes, avec des conséquences sérieuses sur l’ensemble de l’organisation (pertes financières, atteinte à la réputation, obligations légales, perturbations opérationnelles, etc.). Une crise cyber exige une gestion centralisée, une communication de crise et l’intervention de plusieurs parties prenantes (DSI, RSSI, direction, communication, juridique…).
| Terme | Gravité | Impact | Action requise |
| Évènement | 🔹 Faible | Potentiel | Surveillance, tri |
| Incident | 🔸 Moyenne | Réel | Investigation, réponse rapide |
| Crise | 🔺 Forte | Systémique | Gestion de crise, coordination |
Le traitement d’incident, c’est la capacité à faire face — à repérer, analyser, gérer, prioriser, et apprendre.
Et cette capacité, elle se révèle surtout quand plusieurs incidents tombent en même temps. C’est là que la question devient vraiment intéressante : comment prioriser les incidents ?
2. La clé : l’impact, pas juste l’alerte
On pourrait croire qu’on classe les incidents selon leur nature : phishing, ransomware, DDoS. Mais ce qui importe vraiment, c’est leur gravité. Et surtout, la valeur des actifs concernés. Une vulnérabilité sur une machine critique, ce n’est pas la même chose que sur un poste lambda.
C’est là qu’intervient le bon sens — et un peu de méthode. Le NIST propose un cadre utile : son Computer Security Incident Handling Guide aide à structurer cette réponse. Mais une chose est sûre : il faut comprendre l’attaque pour y répondre efficacement.
3. Comprendre l’attaque : la chaîne invisible
Les attaques ne surgissent pas de nulle part. Elles suivent un schéma. Un schéma imparfait, itératif, mais utile. C’est ce que montre la Cyber Kill Chain :
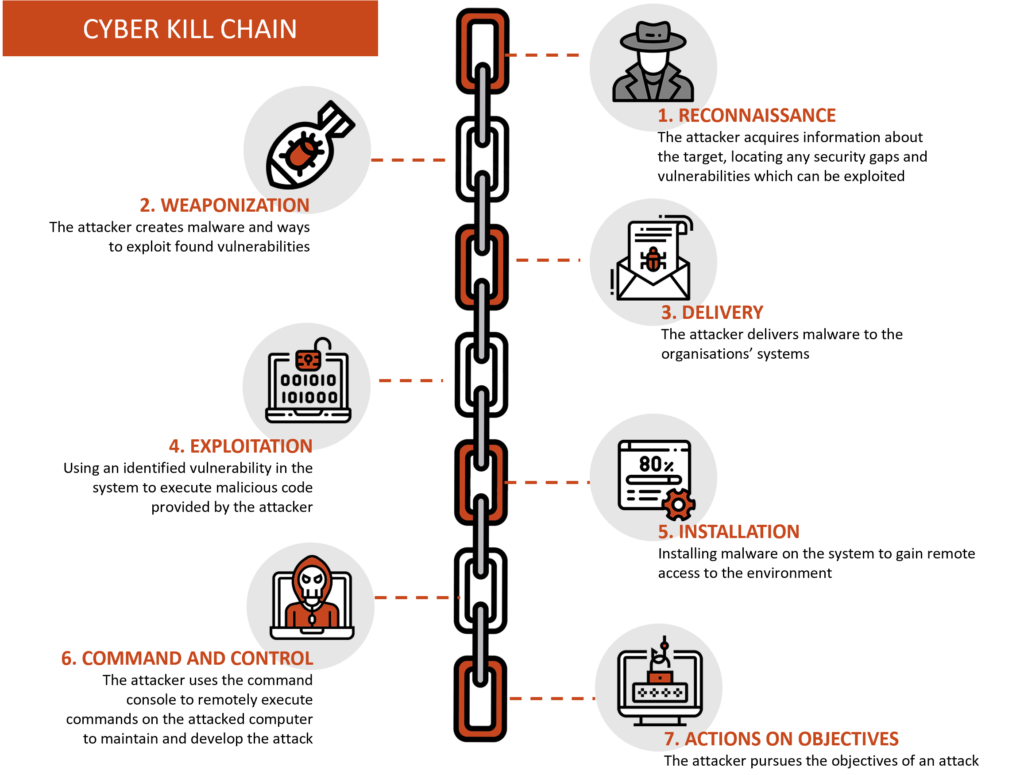
- Reconnaissance
- Armement
- Livraison
- Exploitation
- Installation
- Commande et contrôle
- Atteinte de l’Objectif Visé
Ce n’est pas un chemin linéaire. Les attaquants peuvent revenir en arrière. Chercher une nouvelle faille. S’adapter. D’où l’idée de sécurité en profondeur. Multiplier les couches. Boucher les trous. Penser comme eux.
Et surtout : plus on les arrête tôt dans cette chaîne, mieux c’est.
4. C’est quoi gérer un incident
Les procédures de traitement d’incident ne sont pas là juste pour faire joli. Leur rôle est double :
- Investiguer, en continu : une logique proactive.
- Remédier, quand l’attaque est avérée : une logique réactive.
Et derrière ces deux missions, il y a trois objectifs concrets :
- Retrouver le patient zéro.
- Identifier les techniques utilisées.
- Documenter l’ensemble du périmètre compromis.
Le NIST définit ces process de TI grâce à ce diagramme :
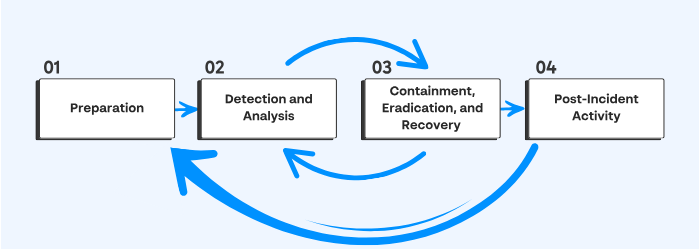
Une fois l’attaque contenue, le Plan de Reprise d’Activité prend le relais. Et les opérations reprennent. Mais pas sans un rapport post-mortem, un retour d’expérience (REX) et des leçons tirées.
5. La préparation : le maillon souvent ignoré
Ironie du sort : la préparation est rarement du ressort direct de l’équipe en charge de la réponse à incident.
Ce qu’il faut :
- Un CSIRT compétent
- Des employés sensibilisés
- Des politiques documentées
- Des outils adaptés (software et hardware)
Et surtout, que tout soit à jour dans les politiques de traitement d’incident:
- Les informations de contacts et les rôles de l’équipe de CSIRT interne
- Les informations de contact des membres de l’équipe de crise
- le service juridique et de conformité
- l’équipe de direction
- le support informatique
- le service des communications et des relations avec les médias
- les forces de l’ordre
- le FAI
- la gestion des installations
- l’équipe externe d’intervention en cas d’incident
- Une politique de réponse à incident, un plan de réponse à incident et des procédures de gestion d’incident
- Politique de partage d’information et ses procédures
- Image back-up du réseau et des systèmes
- Les baselines de la goldent image servent à découvrir les fichiers modifiés et donc à trouver changements effectués sur les configurations.
- Diagramme du réseau
- BDD des assets de l’organisation
- Des comptes utilisateurs privilégiés dédiés à l’incident. Les mots de passe sont reste une fois l’incident résolus et les comptes désactivés
- Capacité à s’acheter du hardware ou software sans passer par le process de procurment
- Cheat sheets Investigation/Forensics
Tout cela doit être prêt AVANT que le feu prenne.
Dans certains cas, prévenir les autorités n’est pas une option, mais une obligation. C’est le cas notamment pour les Opérateurs d’Importance Vitale (OIV), les organisations couvertes par la directive NIS2, ou encore lorsqu’il est question de données personnelles au sens du RGPD. Ignorer cette exigence, c’est prendre le risque d’aggraver une crise déjà en cours.
Autre réflexe essentiel — et trop souvent oublié sous pression : documenter au fil de l’eau. C’est dans les moments de tension que l’on pense le moins à prendre des notes… et c’est justement dans ces moments-là qu’elles deviennent les plus précieuses. La documentation ne devrait jamais être une tâche “à faire plus tard”. Elle doit devenir un automatisme, comme attacher sa ceinture.
Et une fois la remédiation engagée, quand la maison ne brûle plus, les équipes de Forensics peuvent enfin intervenir en profondeur. Elles arrivent avec leurs outils, leurs « jump bags », et leur objectif est clair : comprendre, à froid, ce qui s’est réellement passé. Parce que même si l’incendie est éteint, les traces, elles, sont encore là.
6. Protéger, pour ne pas avoir à réagir
Voici les mesures de protection concrètes, les “briques défensives” :
- Email : DMARC, SPF, DKIM pour bloquer les usurpations
- Systèmes :
- Conformer ses golden images aux CIS benchmarks
- Désactiver LLMNR/NetBIOS
- Mettre en œuvre LAPS et supprimer les privilèges administratifs des utilisateurs réguliers
- Désactiver ou configurer PowerShell en mode « ConstrainedLanguage »
- Activer les règles de réduction de la surface d’attaque (ASR) si vous utilisez Microsoft Defender
- Mettez en place une liste blanche. Nous savons que c’est presque impossible à mettre en œuvre. Envisagez au moins de bloquer l’exécution à partir de dossiers accessibles en écriture par l’utilisateur (Téléchargements, Bureau, AppData, etc.). C’est là que se trouvent initialement les exploits et les charges utiles malveillantes. N’oubliez pas de bloquer également les types de scripts tels que .hta, .vbs, .cmd, .bat, .js, etc. Veuillez faire attention aux fichiers LOLBin lors de la mise en œuvre de la liste blanche. Ne les négligez pas ; Ils sont vraiment utilisés dans la nature comme accès initial pour contourner la liste blanche.
- Utilisez des pare-feu basés sur l’hôte. Au minimum, bloquez les communications entre postes de travail et bloquez le trafic sortant vers les LOLBins
- Déployer un EDR. À l’heure actuelle, AMSI offre une grande visibilité sur les scripts obfusqués pour que les produits anti-malware inspectent le contenu avant qu’il ne soit exécuté. Il est fortement recommandé de ne choisir que des produits qui s’intègrent à AMSI.
- EDR : choisir ceux compatibles avec AMSI
- Réseau : segmentation, DMZ, IDS/IPS avec déchiffrement SSL
- Contrôle d’accès : MFA, PAM, passphrases longues « i LIK3 my coffeE warm »
- Vulnérabilités : scans en continu, mesures compensatoires si pas de patch
- Active Directory : audits réguliers
- Exercices Purple Team : tester et former les défenses avec des Red/Blue Teams
7. Détecter, ce n’est pas tout comprendre
Un incident peut venir de n’importe où : un employé, une alerte SIEM, l’équipe de Threat Hunting, un partenaire. Mais dès qu’il est là, il faut poser les bonnes questions :
- A quelle jour/heure à eu lieu l’incident ?
- Qui a détecté l’incident et l’a signalé ?
- Comment l’incident a-t-il été detecté ?
- Comment peut-on catégoriser l’incident ? Phishing ? Perte de disponibilité ? Vol de données ?
- Quels systèmes ont étés impacté et comment ont-ils étés impactés ? Faire un tableau.
- Qui a eu accès à ces systèmes ? Quels actions ont étés réalisées ?
- Est-ce que l’incident est encore en cours ou est-ce qu’il a été résolu ?
- Pour chaque système :
- Localisation géographique
- OS
- IP addresse et hostname
- propriétaire du système
- Valeurs métiers du système
- état du système
- Si malware
- Liste des addresses IP
- Jour et heure de la détection
- Type de malware
- Systèmes impactés
- Export des fichiers malicieux avec les infos forensiques
À partir de là, on construit la timeline.
| Date | Heure | Hostname/IP | Description de l’évènement | Source de la donnée |
| 09/09/2021 | 13:31 CET | SQLServer01 | Hacker tool ‘Mimikatz’ was detected | Antivirus Software |
Pour prioriser les incidents dans le SOC, il est aussi important d’évaluer la gravité des incidents, et il faut donc se poser plus de questions :
- Quel est l’impact de l’exploitation ?
- Quelles sont les exigences en matière d’exploitation ?
- Des systèmes critiques (ou SIE) de l’organisation peuvent-ils être affectés par l’incident ?
- Y a-t-il des suggestions d’étapes de remédiation ?
- Combien de systèmes ont été touchés ?
- Qui est l’attaquant :
- L’exploit est-il utilisé dans la nature ?
- L’exploit a-t-il des capacités similaires à celles d’un ver ?
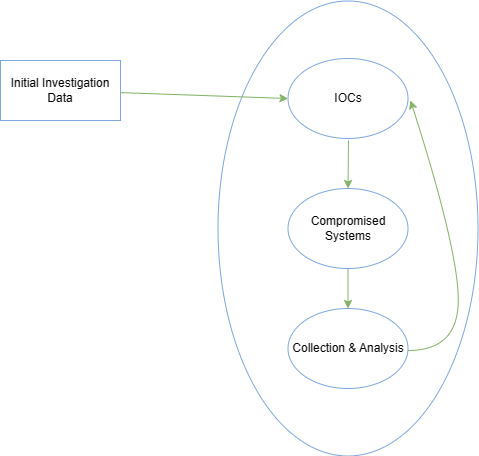
8. L’investigation : un jeu de piste
L’investigation suit un cycle :
- Création des IoC : IPs, fichiers, hash
- Recherche de nouveaux systèmes compromis
- Analyse des nouvelles données
Les outils : Yara, WMI, PowerShell, PsExec, etc. Et la prudence : ne pas polluer les machines avec nos propres traces.
Et pour que ces IoC servent à quelque chose, encore faut-il aller les chercher là où ils se trouvent. Cela implique de scanner les machines, de fouiller, d’extraire les indices. Sur un environnement Windows, ça veut dire : WMI, PowerShell, et tout autre outil capable de creuser au bon endroit.
Mais avec un grand pouvoir vient une grande responsabilité. Quand on se connecte à ces systèmes, surtout avec des comptes alloués au traitement d’incident, on laisse des traces. Et ces traces peuvent poser problème, surtout si elles finissent par brouiller les pistes ou donner des idées à l’attaquant.
D’où la règle : ne jamais utiliser ses super credentials à la légère. On privilégiera des connexions propres, comme WinRM, des logons réseau (type 3), ou encore PsExec sans mot de passe, via la session d’un utilisateur déjà actif. L’objectif, c’est de passer, d’agir, et de ressortir — sans bruit.
9. Endiguer sans alerter l’attaquant
Petit rappel du super diagramme du NIST pour ne pas oublier où on se trouve (on est à l’étape 3) :
Il y a deux temps dans l’endiguement :
Court terme : agir vite, mais sans bruit
Dans une phase d’endiguement, la rapidité compte. Mais la coordination, elle, est cruciale. Il ne suffit pas d’agir vite : il faut que tout soit fait en même temps. Sinon, l’attaquant risque de comprendre qu’il a été repéré. Et à ce moment-là, il change de stratégie. Il devient plus discret, plus difficile à suivre, plus dangereux.
Il faut donc frapper d’un seul coup, sans donner l’alerte.
Parmi les gestes à envisager :
- Isoler la machine sur un VLAN spécifique
- Débrancher le réseau, physiquement
- Rediriger le nom DNS du serveur de commande (C2) vers une machine que l’on contrôle
Et puisqu’on y est — si certaines preuves n’ont pas encore été sauvegardées, c’est maintenant ou jamais. On profite de ces actions d’endiguement court terme pour capturer ce qui pourrait disparaître à jamais.
Long terme : quand on consolide vraiment
Une fois le premier choc absorbé, on entre dans une phase plus réfléchie : celle des mesures durables. L’objectif n’est plus simplement de stopper l’attaque, mais de renforcer les défenses pour éviter qu’elle ne se reproduise.
Parmi ces actions de fond :
- Changer tous les mots de passe concernés
- Appliquer de nouvelles règles de firewall
- Patcher les systèmes vulnérables
- Déployer des IPS pour bloquer des attaques similaires
Mais attention : patcher ne suffit pas. Un système corrigé n’est pas un système sain. Il reste à faire le ménage — à éradiquer les traces de l’attaque, à remédier aux impacts, puis à analyser tout ce qui s’est passé.
Ce n’est que là que le véritable travail sera terminé.
10. Éradication : le vrai nettoyage commence ici
Une fois que l’attaquant est contenu, que ses accès sont coupés, il reste encore à nettoyer les lieux. C’est ça, l’éradication : faire disparaître toute trace de sa présence.
Cela veut dire :
- Supprimer les malwares
- Reconstruire les systèmes compromis
- Restaurer depuis les backups sains
- Appliquer les patchs restants (ceux qu’on n’a pas osé toucher dans l’urgence)
- Et surtout : durcir l’ensemble de l’infrastructure, même celle qui n’a pas été visée directement
L’idée est simple, presque naïve : faire en sorte que la même attaque ne puisse plus réussir. Mais pour y parvenir, il faut reprendre le contrôle de chaque maillon du système, un à un.
11. Remédiation : reconstruire, mais en mieux
C’est la dernière ligne droite. Le moment où l’on remet les systèmes en production. Le métier teste, vérifie, redémarre. Et pourtant, tout n’est pas terminé.
Car ce retour à la normale est fragile. L’attaquant pourrait revenir, tenter à nouveau, avec les mêmes techniques ou d’autres. C’est pour cela que les systèmes restaurés doivent être mis sous surveillance renforcée.
Quelques signaux à surveiller :
- Des connexions inhabituelles (logons anormaux)
- Des services ou utilisateurs qui apparaissent là où ils ne devraient pas
- Des processus étranges
- Des modifications dans le registre, typiquement ciblées par les malwares
La remédiation, dans un grand système d’information, peut prendre des mois. Ce n’est plus une phase de réaction rapide : c’est un travail de fond, parfois lent, souvent invisible, mais essentiel pour repenser durablement la posture de sécurité.
12. Post-Incident : comprendre pour ne plus subir
Quand tout semble enfin terminé, une autre mission commence. Il faut prendre du recul, revenir sur les faits, comprendre ce qui s’est passé et pourquoi.
Ce travail s’appelle un REX : retour d’expérience. C’est une introspection à l’échelle de toute l’organisation.
Le rapport produit doit répondre à des questions simples, mais fondamentales :
- Qu’est ce qui s’est passé ?
- Quand est-ce que ça c’est passé ?
- REX sur la performance de l’équipe de traitement d’incident en ce qui concerne les plans, les playbooks, les politiques et les procédures.
- Quelles actions ont étés implémentées pour contenir et éradiquer les assets attaquants ?
- Quelles mesures préventives ont étés mises en place pour prévenir ce genre d’incident à l’avenir ?
- Quels outils et ressources sont utilisées pour détécter et analyser plus tôt ce genre d’incident à l’avenir ?
Ce type de rapport est bien plus qu’un document pour les archives. C’est une source d’apprentissage, un miroir tendu à l’équipe, une base pour mesurer ce qui fonctionne — et ce qui doit changer.
C’est aussi un outil de transmission : les plus jeunes peuvent y découvrir comment les anciens ont géré des crises réelles. On n’apprend pas mieux que par l’exemple, surtout quand il est vécu.
Alors gravez ce schéma dans un coin de votre tête.
Ressortez-le de temps en temps. Il vous rappellera ce que vous affrontez… et comment ne pas se faire submerger.
Laisser un commentaire