

Bonjour à tous et merci de prendre le temps de lire cet article.
Premièrement, j’ai envie de poser un axiome : l’intelligence artificielle, telle que nous l’entendons aujourd’hui, n’est PAS intelligente dans le sens anthropomorphique du terme (traduction : l’IA n’est pas intelligente de la même manière dont nous, êtres humains, la concevons).
Je ne vais pas entrer dans les aspects mathématiques avec les matrices, vecteurs, réseaux de neurones pour essayer de le prouver. Je vais simplement dire que les systèmes d’IA (ML, DL, LLM, générative, etc.) ne font que recevoir un grand nombre de données en entrée (interprétées pour devenir des vecteurs) afin de PRÉDIRE des sorties (des vecteurs interprétés).
Les taquins diront que c’est de cette manière que nous, êtres humains, fonctionnons : avec nos sens qui deviennent des signaux électriques, interprétés par notre matière grise, puis retransmis, encore sous forme de signaux électriques, pour que nous puissions répondre grâce, une fois de plus, à nos sens.
Seulement, je leur réponds, avec un ton taquin : « Je ne sais pas. » Même les plus grands neurologues ne savent pas précisément comment les centres nerveux humains fonctionnent.
En revanche, nous savons exactement comment fonctionnent les systèmes d’intelligence artificielle, puisque nous les avons créés (pas moi personnellement, mais vous avez l’idée).
Aujourd’hui, en ce 14 mai 2025, l’humanité perçoit les SIA (systèmes d’IA) comme de gros blocs monolithiques que l’on appelle modèles de LLM. Ces modèles sont bien souvent entraînés pour être des modèles généralistes que l’on « fine-tune », ou que l’on « prompt », dans le but (au mieux) de les spécialiser.
Cette vision doit et va changer, parce que ce ne sont pas des systèmes viables, ni durables (au sens ‘sustainable’ – voir les cours de RSE).
Pour donner une idée de la puissance de calcul littéralement gaspillée, ce serait comme essayer de réaliser une frappe chirurgicale en déployant tout l’arsenal nucléaire des États-Unis sur un seul point précis.
Point positif : on a touché la cible.
Point négatif : à quel prix ? Et avec quels dommages collatéraux ?
Donc, qu’est-ce que je suis en train de raconter ? Est-ce que j’ose prétendre à la fin de notre cher ChatGPT ?
Absolument pas !
Je cherche seulement à souligner l’absurdité de devoir gaspiller une bouteille d’eau entière pour que ChatGPT réponde à mon « Bonjour ChatGPT » par « Bonjour 🙂 ».
Et c’est là que naît une nouvelle discipline : l’architecture IA.
Parce que oui, l’IA est un terme généraliste qui inclut les LLM, mais qui comprend surtout un grand nombre d’autres concepts et composantes (des composantes qui, pour la plupart, ont précédé les LLM).
Dans cet article, nous allons explorer comment ont été conçues les architectures IA :
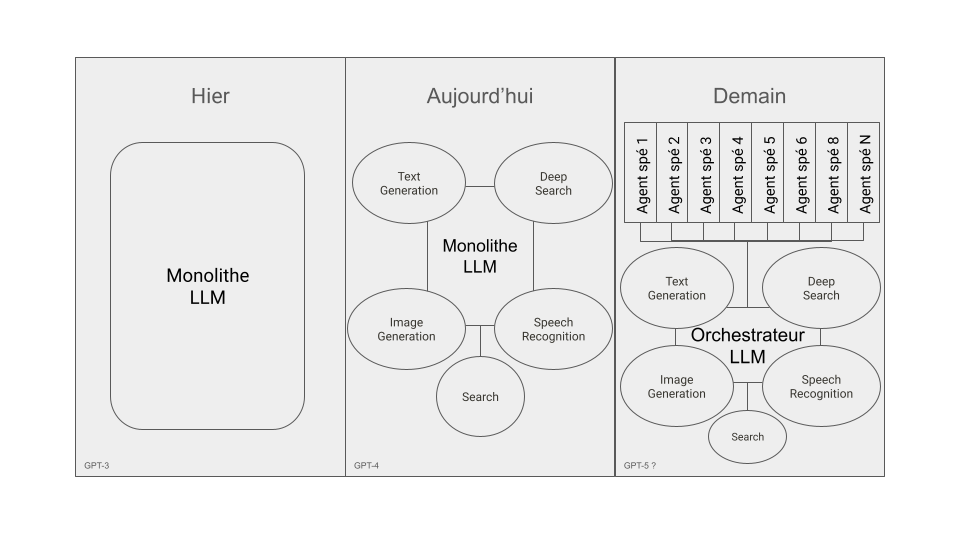
- D’hier (monolithique – LLM)
- D’aujourd’hui (hybride)
- De demain (distribué)
Et pour que tout le monde puisse suivre, nous allons prendre l’exemple de ChatGPT.
Hier
À l’époque, les LLM étaient des monstres monolithiques, bâtis autour d’un paradigme construit sur quatre piliers :
- Architecture
- Neurones
- Données d’entraînement
- Poids du modèle
On ne cherchait pas l’élégance, on cherchait la puissance brute.
Architecture : imagine une toile d’araignée géante, une vraie cathédrale de neurones interconnectés. L’idée était simple : plus de profondeur (plus de couches), plus de largeur (plus de neurones par couche). On empilait, on élargissait, on tissait encore et encore. Plus de connexions = plus d’intelligence.
Neurones : l’arrivée des Transformers a tout changé. Jusque-là, les réseaux neuronaux se contentaient de lire les informations de façon séquentielle, un mot après l’autre. Les Transformers, eux, ont permis de tout lire en même temps, de capter les relations à longue distance grâce au mécanisme d’attention. Exemple : « J’ai mis le gâteau dans le four et il était super bon ». Le modèle comprend que « il » fait référence au gâteau, pas au four. C’était une révolution. On pouvait enfin comprendre les dépendances complexes dans le texte.
Données d’entraînement : le secret de ces modèles ? Les gaver de données. Des livres, des articles, des pages web, des rapports techniques… Plus les données étaient nombreuses, plus le modèle pouvait généraliser, contextualiser, prédire. C’était une course à l’accumulation. On ne filtrait pas, on ingérait tout.
Poids du modèle : la course était à celui qui aurait le plus de paramètres. GPT-2 : 1,5 milliard de paramètres. GPT-3 : 175 milliards de paramètres. On empilait les connexions, les couches, les réseaux. Plus gros, plus lourd, plus puissant. L’objectif était simple : plus de neurones, plus de données, plus de puissance brute, sans trop se soucier de l’efficacité.
Aujourd’hui
Aujourd’hui, l’ère du monolithique n’est pas finie. Elle s’est même renforcée. Le gros cerveau centralisé est toujours là. ChatGPT, Bard, Claude… tous reposent sur un LLM géant, un chef d’orchestre qui contrôle tout.
Ce qui a changé, ce ne sont pas les capacités internes du modèle, c’est ce qu’on lui a ajouté autour. On ne parle pas de véritables modules indépendants, mais plutôt de fonctions externes.
Comme des petits bras mécaniques qu’on aurait greffés au modèle pour qu’il puisse attraper ce qu’il n’arrive pas à atteindre tout seul.
Reprenons l’exemple de ChatGPT, on peut voir les fonctions disponibles dans GPT-4 :
- Search : pour aller chercher l’information en temps réel, notamment sur le web, parce que le réseau neuronal ne peut pas le faire lui-même.
- Deep Research : pour creuser dans les sujets complexes en puisant des informations un peu partout et en raisonnant en plusieurs étapes, un peu à la manière de Manus AI.
- Text Generation : ça, c’est son cœur de métier, rien de nouveau sous le soleil de Dieu.
- Image Generation : on a rajouté un bras artistique pour qu’il puisse dessiner quand on le lui demande. En réalité, il transforme notre texte en prompt pour un agent artistique à la Midjourney.
- Speech Recognition & Generation : un module greffé pour écouter et parler, parce que sans ça, il est sourd et muet.

On vend ça comme de la modularité. En réalité, ce sont juste des extensions.
Le LLM reste le même au centre, encore plus massif que GPT-3. On ne l’a pas allégé, on l’a équipé.
Et les quatre piliers de « Hier » sont toujours là, intacts, mais sous stéroïdes :
Architecture
Toujours cette gigantesque toile d’araignée neuronale qui orchestre tout. Sauf qu’on a rajouté des modules autour, un peu comme des extensions web sur un navigateur.
On a même ajouté de la récursivité dans le passage de l’information, histoire de bien faire transiter les calculs plusieurs fois dans les mêmes couches, pour maximiser le ballet énergétique.
Parce que oui, l’arrivée de ces fameuses fonctions externes (Search, Image Generation, Data Analysis, etc.) n’a pas simplifié le parcours de l’information, elle l’a complexifié.
Quand tu envoies une requête à un LLM moderne, voilà ce qu’il se passe : le modèle principal reçoit la question, l’interprète, et décide s’il a besoin d’activer l’un de ses petits bras droits.
Si tu lui demandes « Quel est le prix actuel de l’action Tesla ? », il sait qu’il n’a pas l’info en mémoire. Il appelle donc la fonction Search, qui elle-même déclenche une recherche sur le web. Jusque-là, tout va bien.
Sauf que cette recherche externe ne revient pas toute seule, elle repasse par le LLM, qui doit réinterpréter les résultats, les reformater, les comparer à ce qu’il connaît déjà.
Et là, on entre dans la récursivité. Le LLM relance une passe sur les mêmes couches neuronales, pour redigérer l’information. C’est un peu comme si tu relisais le même paragraphe dix fois pour être sûr de l’avoir compris.
Et ce n’est pas fini. Si la requête est complexe, le LLM peut décider de réutiliser les informations issues de la première passe pour déclencher un appel à un autre module, par exemple Deep Research.
Cette nouvelle requête génère un autre traitement, qui repasse une nouvelle fois par le LLM central pour être reformulé, recontextualisé, réinterprété.
C’est une boucle.
Une récursivité volontaire, optimisée (en théorie) pour enrichir la réponse, mais qui en réalité crée une cascade de calculs sur les mêmes couches denses du modèle central, encore et encore.
Un seul appel peut provoquer trois, quatre, cinq passages successifs dans le modèle obèse, juste pour formater les réponses des modules et les intégrer dans le flux de génération.
En pratique, cette récursivité multiplie les calculs, double les allers-retours d’information, et gonfle la consommation énergétique.
On fait passer le même vecteur dans les mêmes réseaux, juste pour que les informations se « synchronisent » correctement.
Le modèle ne se contente pas de récupérer le résultat brut d’un module, il le repasse au crible de ses neurones, parfois plusieurs fois, pour vérifier la cohérence, réécrire, ajuster.
C’est un ballet, oui, mais un ballet énergivore. On nous vend l’idée d’une architecture plus modulaire, mais en vérité, chaque module déclenche une avalanche de calculs récursifs dans le LLM central.
On ajoute de la complexité là où on aurait pu simplifier.
Neurones, données d’entraînement et poids du modèle
Neurones : GPT-4 repose toujours sur l’architecture Transformer, avec les mêmes mécanismes d’attention que ses prédécesseurs. Pas de révolution sous le capot, juste une version XXL de ce qui existait déjà. On a pris GPT-3, on l’a gonflé, on a étiré les couches, densifié les connexions, et ajouté encore plus de neurones. Le modèle est plus large, plus profond, plus massif. Mais la mécanique reste la même : le mécanisme d’attention, traitement séquentiel, prédiction mot par mot. Plus de neurones, plus de paramètres, mais le même cœur.
Données d’entraînement : GPT-4 a été nourri comme jamais. On parle de 13 000 milliards de tokens, soit environ 10 000 milliards de mots. Pour donner une idée, c’est l’équivalent de toute la bibliothèque du Congrès des États-Unis, multipliée plusieurs fois. Des livres, des articles, des pages web, de la documentation technique, des forums, tout ce qui pouvait être trouvé a été avalé, digéré, transformé en vecteurs. La stratégie n’a pas changé : plus de données = plus de capacité à généraliser. Pas de tri, pas de filtrage intelligent, juste du gavage massif.
Poids du modèle : Là encore, on ne parle pas d’allègement. GPT-3 faisait déjà 175 milliards de paramètres. GPT-4 ? On estime à 1,8 trillion de paramètres. 1,8 trillion = 1 800 milliards. On a changé d’échelle, littéralement. Les milliards de connexions se sont empilés, les réseaux neuronaux se sont densifiés, l’infrastructure a gonflé. Les serveurs ont dû suivre, les centres de données ont pris du volume, et la facture énergétique également.
Demain
Demain, l’idée même du gros cerveau centralisé, ce LLM monolithique qui fait tout, va disparaître pour laisser place à un véritable écosystème d’IA : le MoE (Mixture of Experts).
On va enfin sortir de cette logique absurde de scaling vertical, cette course insensée au « plus gros, plus profond, plus lourd ». Un peu comme si, pour régler un problème de fuite d’eau, on décidait de rescussiter Einstein, alors que le plombier du quartier est juste en bas.
GPT-5 (ou peu importe le nom qu’on lui donnera) ne sera pas un modèle géant. Ce sera un écosystème. Une constellation de cerveaux spécialisés, chacun conçu pour exceller dans un domaine précis.
C’est de la modularité, mais pas celle à laquelle on a été habitué. On ne parle plus de fonctions « branchées » sur un monolithe central, comme c’est le cas aujourd’hui avec Search, Image Generation ou Data Analysis. On parle de modularité dans l’expertise.
Quand tu poseras une question complexe, ce ne sera plus un seul modèle qui essaiera de tout faire.
Le LLM principal, bien plus léger que ne le sont les modelès aujourd’hui, agira comme un routeur intelligent, identifiant les agents spécialisés nécessaires, orchestrant leurs réponses, et les assemblant pour donner le résultat final.
Un peu comme un bon chef d’orchestre : il ne joue pas de tous les instruments, il dirige ceux qui savent le faire. Pour une question de droit, l’agent « droit » est activé. Pour une requête médicale, l’agent « médecine » entre en scène, etc.
C’est comme passer d’un gratte-ciel qu’on empile toujours plus haut (scaling vertical) à une ville entière, répartie horizontalement (scaling horizontal). Plus besoin de renforcer la structure à chaque étage supplémentaire. On construit à côté, on démultiplie les experts, on répartit la charge. On étend l’intelligence au lieu de la tasser dans un même bloc.
Les quatre facteurs qui définissaient les LLM d’hier ? Ils n’existeront plus dans ce modèle distribué :
- L’architecture monolithique : elle éclate en une série de micro-modèles, plus légers, plus spécialisés. Plus besoin d’un cerveau géant, on a des milliers de cerveaux plus petits, chacun dans sa spécialité. On segmente pour ne plus avoir à tout activer.
- Les trillions de neurones Transformers : géants, coûteux, énergivores. Demain, ils deviendront modulaires. On n’activera que ceux dont on a besoin, les autres resteront en veille. Plus de calcul inutile.
- Les données d’entraînement : fini le gavage massif. Chaque micro-modèle apprend ce qu’il doit apprendre, pas plus. L’expert en droit se nourrit de textes juridiques, l’expert médical de recherches médicales, etc. On ne surcharge plus un modèle généraliste avec de l’information qu’il n’utilisera jamais.
- Le poids du modèle : on l’oublie. On ne parle plus en milliers de milliards de paramètres, mais en agents légers et autonomes, chacun avec ses propres spécifications. Plus de modèle obèse qui doit tout porter sur ses épaules.
On sort du « tout ou rien ». Le modèle ne brûle plus de l’énergie pour une simple requête. Chaque agent s’active uniquement quand il a un rôle à jouer.
Besoin d’une analyse économique ? On appelle le module concerné, les autres dorment. Besoin d’un résumé littéraire ? L’expert en littérature s’active, et personne d’autre.
Demain, l’intelligence artificielle ne sera plus un monolithe glouton, mais un réseau distribué, modulaire, frugal. Un peu comme une colonie de fourmis : chacun fait sa part, et l’ensemble fonctionne mieux.
Pas de redondance, pas de gaspillage, juste de l’efficacité collective.
Et là, on pourra enfin parler d’Architecture IA. Pas juste d’un gros bloc qu’on alimente jusqu’à l’indigestion, mais un écosystème intelligent, flexible et sobre.
Dernier mot
Merci d’avoir lu ce « manifeste » jusqu’au bout. Voici un schéma pour tout illustrer :
Laisser un commentaire