
Temps de lecture : 25 minutes
Tout le code associé à ce projet est disponible sur Github ici : https://github.com/Tarekinh0/IndoorBigBrother
Introduction
Imagine.
Un monde où on peut tracer chacun de ses collaborateurs, à la salle près dans un immeuble.

Effrayant… et un peu glauque. Mais on l’a fait !
Ce projet est un projet de géolocalisation Indoor, qui s’oppose à la géolocalisation Outdoor, qui elle tourne autour des systèmes GNSS (Global Navigation Satellite System – dont le GPS américain, Glonass russe et Galileo européen).
On en parlera un jour d’ailleurs des systèmes GNSS, c’est super intéressant !
Mais pour l’instant l’Indoor !
Théorie
Contexte
Alors. Depuis votre entreprise (si vous êtes dans une grosse boîte ou dans un grand immeuble), ouvrez vos paramètres sur votre téléphone et regardez les réseaux autour de vous. Vous allez sûrement en trouver au MAXIMUM une dizaine.
Quelques uns sont propres à votre entreprise, d’autres sont à d’autres entreprises environnantes et enfin quelques unes, probablement des partages de connexion de quelques personnes singulières.
En fait, ce que vous voyez c’est les ESSID, le nom des réseaux disponibles dans la zone. Alors que le BSSID, ça va être l’adresse MAC de l’appareil.
Seulement nuance… Un seul réseau peut avoir plein de points d’accès. C’est ce qu’on appelle le mode multi-SSID. Grosso modo, on met tout plein de point d’accès un peu partout, on les connecte au routeur et on configure 2 ou 3 réseaux dessus, généralement avec différents niveaux de sécurité (un « Guests », un « Employés » et un « Administrateurs » peut-être).
Donc en soit le mode multi-SSID permet d’allier plusieurs BSSID sur un seul ou plusieurs ESSID.
Le but est double :
- Rendre le réseau physique plus accessible et disponible
- Cloisoner le réseau
Donc comment, nous, Big Brother, allons exploiter ce sytème ?
Et bien on va faire ce que les séries appellent Triangulation, mais qui est scientifiquement appellé : Trilateration
Donc ça donne ça :
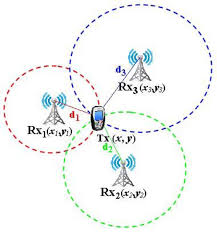
On va mesurer les puissances perçues (ou reçues) des points d’accès FIXES.
Notre position est relative par rapport à la puissance des antennes qu’on captes. Si on veut avoir une position absolue par rapport à l’immeuble ou le bâtiment, il faut que la position des antennes soient fixes dans l’immeuble.
Dans le mot trilatération, on a le préfixe Tri qui signifie trois.
Seulement problème : Le signal subit une atténuation non linéaire et impossible à prévoir 🙁
3 problèmes en découlent :
- Trois antennes (ou points d’accès) ; c’est pas suffisant.
- Il faudra reprendre des mesures de manières régulières parce que la perte de puissance de signal évolue selon les jours, le nombre de personnes présentes au moment de la mesure, l’activité aux alentours, etc. etc.
- La puissance perçue dépend aussi bien de l’émetteur que du récepteur. Donc je dois m’assurer de faire les mesures avec la même carte réseau que la personne que je veux tracer.
Solutions :
- On a énormément de points d’accès, ça se compte en centaine donc ça devrait le faire.
- Si je fais les mesures un mercredi à 11h, mon modèle est plus susceptible de bien fonctionner les mercredi à 11h que les lundi à 17h parce que mon environnement sera le plus similaire.
- Généralement, on n’a pas de BYOD en entreprise et on nous fournit des ordinateurs achetés en gros. Donc j’ai sûrement le même modèle d’ordinateur que les collègues que je souhaite tracer.
Plan d’action
Donc le plan d’action pour suivre les gens à la trace.
Tout d’abord. Je crée mon plan avec mes différentes zones.
Ensuite, je me balade dans la zone en prenant quelques centaines de mesures (200 ou 300 suffisent largement). Mes mesures consisteront en plusieurs couples BSSID:RSSI.
RSSI : à ne pas confondre avec RSSI (Responsable de la Sécurité du Système d’Information). RSSI ici veut dire Received Signal Strength Indicator. Donc la Puissance en dB.
Bref…
Je vais donc me balader dans toutes mes zones et mesurer. Je sépare les mesures par zones.
Si j’ai X zones et Y mesures.
- Je crée X dossiers zones et dans chaque dossier, j’aurai Y fichiers mesures.
- A partir de ça, je formatte mes données pour les donner aux modèles.
- Je nettoie ensuite mes données. Exemple : si je vois « Iphone de Sammy », j’en veux pas, je veux juste prendre les appareils Cisco dans le coin, donc les appareils fixes et statiques.
- J’entraine mes modèles et je test !
J’ai donc créé les 4 fichiers nécessaires, vous les trouverez sur mon Github en suivant ce lien : https://github.com/Tarekinh0/IndoorBigBrother
Mais ne vous inquiétez pas, on va tout revoir, étape par étape, à la mano !
Pratique
Revue des étapes
Donc rappelons les étapes :
Le projet a été mené en plusieurs phases:
- L’acquisition des données dans plusieurs salles.
- Le traitement des données pour les rendre ingérables par les modèles.
- Le nettoyage des données pour enlever toutes les données qu’on juge problématiques (soit
rajoutent beaucoup de complexité, soit qui sont dues à des erreurs). - Séparer les données d’entraînement et les données de Test.
- Entraîner les modèles.
- Rétrotest les modèles (essayer le modèle sur les données acquises et mesurer dans la première étape).
- La mise en place du test en temps réel.
Tout ce qu’on a fait jusque là c’est de la théorie. En tant qu’ingénieur, mon boulot c’est de respecter un cahier des charges. Respecter le cahier des charges = faire le plus simple possible pourvu que ça respecte mon cahier des charges ; c’est ça la mentalité ingénieur.
J’ai donc décidé de mener ce projet sur la stack suivante :
- Linux (intéraction avec la carte réseau ou NIC beaucoup plus simple)
- Python (simple)
- scikit-learn (on va pas se tordre sur tensorflow sur un projet aussi simple et basique)
Alors attention ; il est super possible de faire ce projet en C++ sur Arduino. Ca serait même super marrant de le faire. Alors oui, on aura sûrement besoin de faire les calculs deep learning sur une machine spécifique plus haut dans le réseau (du genre un serveur centrale, ce serveur peut absolument être mon PC portable).
Mais là, on veut juuuste faire simple.
Allons-y !
Acquisition des données (localiser.py)
Attention : Notez bien le jour et l’heure auquel vous prenez les mesures.
C’est ici que nous allons justifier de l’utilisation d’un système d’exploitation GNU+Linux.

On utilise ce système pour avoir accès au bash, qui nous permet, sans librairie tierce d’interagir avec la carte réseau. C’est aussi un système plus universelle et accessible.
On va mesurer le RSSI vis-à-vis de chaque Basic Service Set (BSSID – ici c’est le BSS ou Point d’accès sans fil). Donc grosso modo, la puissance perçue.
En ce qui concerne l’architecture de nos données, pas de Excel ; Ici on parle en csv et en dossiers.
On a définit 10 zones et dans chacune de ces zones on va prendre 120 mesures éparpillées un peu partout dans cette salle.

Et dans chaque zone, un fichier CSV.
En voyant le code, vous trouverez du bash. Si vous n’êtes pas familier avec, contactez moi (ou chatGPT, il sera sûrement plus pédagogue que moi).
Le code est fait de manière à ce que un scan est lancé toutes les 2 secondes; à vous de couvrir l’entièreté de la salle en 240 (120 scans configurés fois 2 secondes). Attention, baladez vous lentement et prévoyez un plan pour naviguer à travers l’entièreté en balayant un maximum de surface.
Pas d’explications pour le code, j’écris ça à 23h45, je veux dormir et franchement vous cassez pas la tête à cherchez à répliquer le projet si vous n’arrivez pas à comprendre les tenants et les aboutissants de ce code (j’insiste, contactez moi, je suis mignon et gentil d’habitude : tarek@mahfoudh.net)
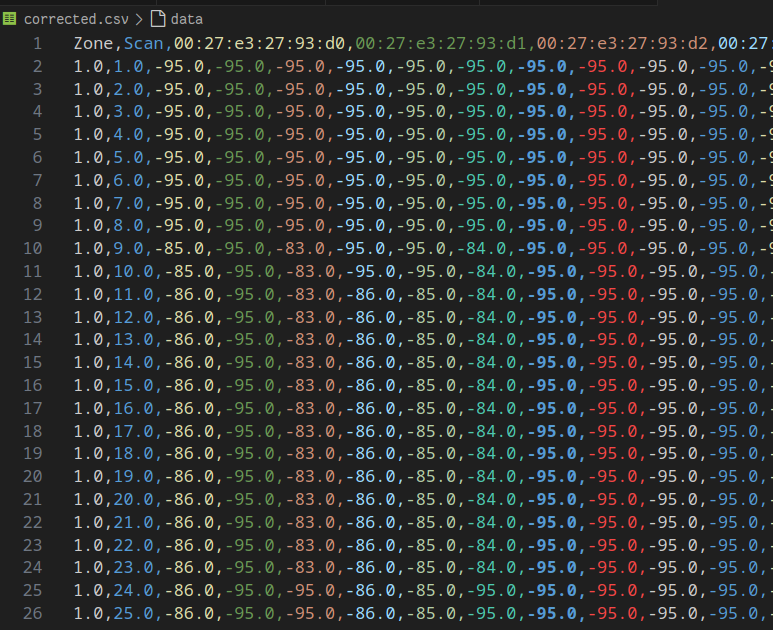
On termine donc cette première partie avec des entrées de ce genre :

On interprète ça de la manière suivante. Pour la Y-ième mesure de la zone X, on mesure un RSSI de -73.0 pour le BSSID 84:b2:61:15:36:31. Et dans chaque fichier, on a 120 entrées de ce genre.
Le traitement des données (trier.py)
Maintenant, on a fini la plus physique de ce projet : se balader lentement dans tout le bâtiment. Maintenant on traite nos données pour que le bon gros modèle les mange.
On a des pommes, on fait une tarte aux pommes.
Notre modèle prend en entré des X et des Y.
Donc beaucoup de paramètres d’entrées (les X), notamment le RSSI pour chaque point d’accès détecté durant TOUS les scans. Ce qui implique que mon X aura comme entête de colonne absolument tous les BSSID que j’ai pu rencontrer durant TOUTES mes mesures dans TOUTES les zones.
Donc première étape, répertorier tous ces points d’accès.
Mes Y, ça va être la zone dans laquelle j’ai pris ces mesures.
Voici en agréger mes Y collés à mes X (attention, le numéro de la mesure est en plus, on en a absolument pas besoin).

Quand je finis cette tâche, je dois donc avoir récupérer un GIGA tableau qui ressemble à :
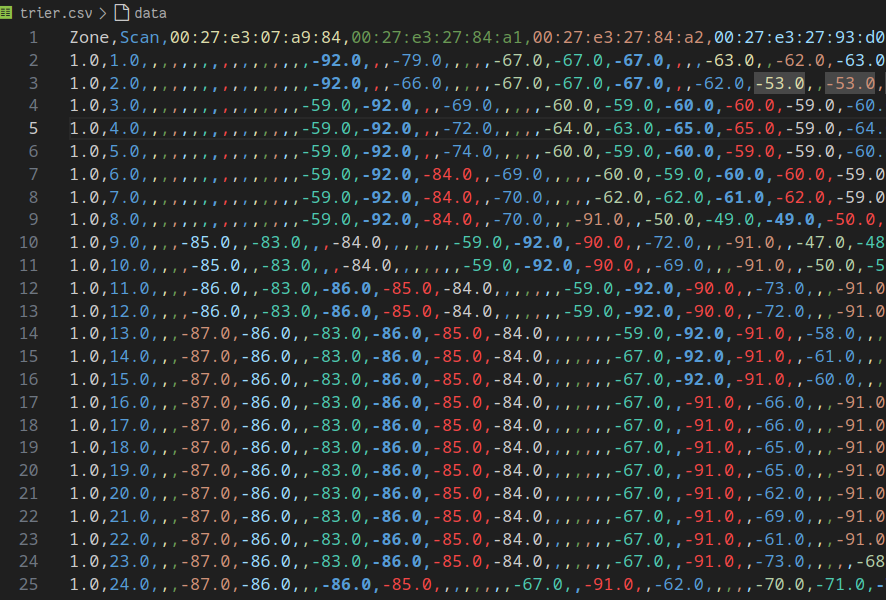
Attention: le fichier est remplie de cases vides et c’est normal.
Nettoyage des données (correction.py)
Pourquoi faire ? Regardons un exemple.
Exemple : Mon établissement est un lycée, l’accès point de la salle des profs n’est détectable QUE dans la salle des profs.
Problçme, mon modèle ne prend pas les valeurs ‘vides’. Donc les ,,,,, qui se suivent, pour lui c’est non.
Et donc, cet access point doit quand même apparaître sur les mesures d’une manière ou d’une autre, même si la zone que j’essaie de prédire est le gymnase du lycée (qui se trouve à l’opposé de la salle des profs).
Je dois donc trouver une manière pour rendre ces mesures visibles au modèle, parce que mon modèle ne prend pas la valeur NULL ou NaN.
Il s’agirait donc de déterminer un 0 qu’on donnerait à toutes les valeurs vides.
Il n’y a pas de 0 absolu en data, la valeur nulle dépend de l’objet de l’étude.
En ce qui concerne les RSSI, le 0 est généralement -95.00 (j’ai aussi vu -97.00 mais oublions ça).
Donc VOILÀ, on va remplacer toutes nos valeurs vides par la sainte valeur -95.00
Maintenant second problème, plus on ajoute de points d’accès dans le process, plus on ajoute de dimensions au problème. Et plus on ajoute de dimensions au problème que devra résoudre notre modèle de deep learning, plus ça prendra du temps et des ressources.
On doit donc chercher à optimiser ce paramètre. Et quoi de mieux que d’effacer des données.

L’idée est donc d’effacer les points d’accès qu’on voit très peu, mais pas assez peu pour qu’il ne soit détectable que dans une zone.
Donc dans notre salle de prof, si le AP spécifique à cette zone appraît 100 fois là bas et 0 partout ailleurs, il serait très bête de se séparer d’un tel avantage !
Mais si, il n’apparaît que dans 5 ou 10 des 120 mesures…

On l’efface lui et sa colonne.
On met les 2 stratégie en place.
On termine avec un plus joli tableau :
Séparation des données d’entraînement et de test (testModels.py)
Très, très simple :
X_train, X_test, Y_train, Y_test = train_test_split(X, Y,
test_size=0.2, random_state=42)80% des données récoltés seront utilisées pour l’entraînement, 20% seront utilisés pour mesurer la précision de nos modèles.
Rétro test des modèles (testModels.py)
Mais du coup, de quels modèles on parle ?
On va implémenter et comparer 3 modèles :
- SVM
- MLP
- KNN Manhattan
- KNN Euclidian
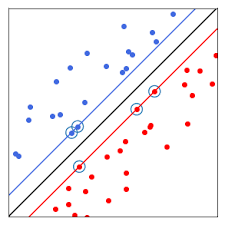
SVM
Imagine que tu as un tas de points sur une feuille, et ces points appartiennent à deux catégories différentes (par exemple, rouges et bleus). Le but de SVM est de tracer une ligne (ou, dans un espace plus compliqué, un plan ou une surface) entre ces points de manière à séparer les rouges des bleus le mieux possible. Ce qui est important pour SVM, c’est que cette ligne soit placée de façon à maximiser l’espace (la marge) entre les deux groupes de points. Si les points ne peuvent pas être séparés simplement, SVM peut transformer les données pour les rendre séparables dans un espace plus complexe.
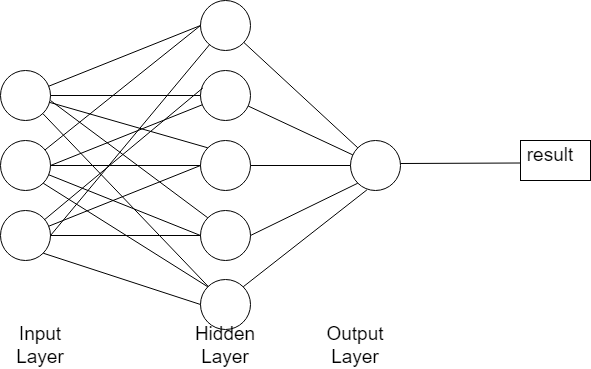
MLP
Réseaux de neurones, seulement, contrairement aux CNN ANN et autres DNN, on a peu de couches intermédiaires (ou cachés).
Pour une explication plus simple, on peut dire qu’un Multilayer Perceptron (MLP) est un réseau de neurones artificiels. Imaginez un groupe de personnes qui essaient de deviner quelque chose ensemble. Chaque personne (un neurone) prend des décisions simples, puis partage cette information avec un autre groupe de personnes, et ainsi de suite, jusqu’à ce qu’à la fin, tout le monde se soit mis d’accord sur la réponse.
Un MLP fonctionne un peu comme ça, avec plusieurs couches de « personnes » qui partagent leurs décisions jusqu’à ce que la réponse soit trouvée. Cela permet à l’ordinateur de comprendre des choses plus compliquées (comme reconnaître des images ou des sons), mais il faut beaucoup d’efforts pour l’entraîner correctement.
KNN
K-Nearest Neighbors (KNN) est comme un jeu de « Quel est mon voisin ? ». Si tu veux savoir à quelle catégorie un point appartient (par exemple, rouge ou bleu), tu regardes ses voisins les plus proches. Si la majorité de ses voisins sont rouges, alors tu vas dire que ce point est rouge. Si la plupart des voisins sont bleus, tu diras qu’il est bleu.
Il existe différentes façons de mesurer la « proximité » entre les points :
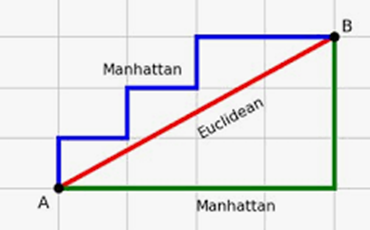
KNNE (Euclidian)
Ici, c’est comme voler en ligne droite d’un point à un autre, sans suivre les rues. C’est la distance la plus courte entre deux points, comme si vous dessiniez une ligne directe (comme le schéma plus haut)
KNNM (Manhattan)
Imaginez que vous marchez dans une ville avec des rues en quadrillage. La distance que vous parcourez est la somme de tous les blocs que vous avez traversés, c’est une distance droite (horizontale ou verticale).
Utiliser un Scaler
Si vous relisez le code, vous verrez qu’on utilise un scaler.
Un Scaler est un outil qui ajuste les données pour les rendre plus comparables. Voici un exemple simple : imaginez que vous devez choisir entre deux candidats pour un travail. Si vous regardez le revenu annuel d’une personne et sa taille en centimètres, ce sont des choses mesurées sur des échelles complètement différentes. Le revenu sera peut-être en milliers, tandis que la taille sera en centaines. Si vous faîtes des calculs basés sur ces valeurs sans les ajuster, le revenu pourrait prendre trop d’importance dans votre choix juste parce que les chiffres sont plus grands.
C’est pareil pour les algorithmes. Si vous ne mettez pas les données à la même échelle (les ajuster pour qu’elles soient toutes sur un même terrain de jeu), certaines variables vont avoir trop de poids par rapport aux autres. Et ça, ça va sûrement donner de mauvais résultats et tout faire foirer.
Résultats
Réussite aux tests
Ils sont tous à quasi 100% donc c’est assez réussi.
Matrice de confusion
Métrique plus intéressante pour juger de la précision des plusieurs modèles.
Une matrice de confusion est un tableau qui montre les performances d’un modèle de classification en comparant les prédictions avec les résultats réels. Pour un problème avec deux classes (par exemple, « positif » et « négatif »), elle se présente ainsi :
| Prédit : Positif | Prédit : Négatif | |
|---|---|---|
| Réel : Positif | Vrais Positifs (VP) | Faux Négatifs (FN) |
| Réel : Négatif | Faux Positifs (FP) | Vrais Négatifs (VN) |
- Vrais Positifs (VP) : Prédictions correctes de « positif ».
- Faux Négatifs (FN) : Le modèle a manqué un « positif ».
- Faux Positifs (FP) : Il a classé à tort un « négatif » comme « positif ».
- Vrais Négatifs (VN) : Prédictions correctes de « négatif ».
Elle permet d’identifier où le modèle se trompe, par exemple en favorisant trop une classe, et de calculer des mesures importantes comme la précision, le rappel, et le score. Cela aide à ajuster le modèle pour améliorer ses performances globales.
Ici, on a une matrice de n fois n, avec n étant le nombre de zones (dans notre exemple 10).
J’explique dans les cas de divergences, quels sont les confusions et erreurs commises par les modèles. Vous pourrez, de cette manière mieux comprendre l’intérêt de ce genre de matrice.
SVM
[[22 0 0 0 0 0 0 0 0 0]
[ 0 24 0 0 0 0 0 0 0 0]
[ 0 0 32 0 0 0 0 0 0 0]
[ 0 0 0 24 0 0 0 0 0 0]
[ 0 0 0 0 20 0 0 0 0 0]
[ 0 0 0 0 0 24 0 0 0 0]
[ 0 0 0 0 0 0 22 0 0 0]
[ 0 0 0 0 0 0 0 28 0 0]
[ 0 0 0 0 0 0 0 0 24 0]
[ 0 0 0 0 0 0 0 0 0 20]]
Aucune confusion n’est présente. Le modèle SVM a parfaitement classé chaque instance
dans sa classe correcte.
MLP
[[22 0 0 0 0 0 0 0 0 0]
[ 0 24 0 0 0 0 0 0 0 0]
[ 0 0 32 0 0 0 0 0 0 0]
[ 0 0 0 24 0 0 0 0 0 0]
[ 0 0 0 0 20 0 0 0 0 0]
[ 0 0 0 0 0 24 0 0 0 0]
[ 0 0 0 0 0 0 22 0 0 0]
[ 0 0 0 0 0 0 0 28 0 0]
[ 0 0 0 0 0 0 0 0 24 0]
[ 0 0 0 0 0 0 0 0 0 20]]
Aucune confusion n’est présente. Le modèle MLP a parfaitement classé chaque instance
dans sa classe correcte.
KNNE
[[22 0 0 0 0 0 0 0 0 0]
[ 0 24 0 0 0 0 0 0 0 0]
[ 0 1 31 0 0 0 0 0 0 0]
[ 0 0 0 24 0 0 0 0 0 0]
[ 0 0 0 0 20 0 0 0 0 0]
[ 0 0 0 0 0 24 0 0 0 0]
[ 0 0 0 0 0 0 22 0 0 0]
[ 0 0 0 0 0 0 0 28 0 0]
[ 0 0 0 0 0 0 0 0 24 0]
[ 0 0 0 0 0 0 0 0 0 20]]
1 instance de zone 3 a été classée comme zone 2.
KNNM
[[22 0 0 0 0 0 0 0 0 0]
[ 0 24 0 0 0 0 0 0 0 0]
[ 0 1 31 0 0 0 0 0 0 0]
[ 0 0 0 24 0 0 0 0 0 0]
[ 0 0 0 0 20 0 0 0 0 0]
[ 0 0 0 0 0 24 0 0 0 0]
[ 0 0 0 0 0 0 22 0 0 0]
[ 0 0 0 0 0 0 0 28 0 0]
[ 0 0 0 0 0 0 0 0 24 0]
[ 0 0 0 0 0 0 0 0 0 20]]
1 instance de zone 3 a été classée comme zone 2, similaire à KNN Euclidien.
Les matrices de confusion révèlent que les modèles KNN ont une légère confusion entre les
classes zone 2 et zone 3, tandis que les modèles SVM et MLP ne montrent aucune confusion. Cette
analyse peut guider les améliorations futures du modèle et la sélection des modèles pour des
applications spécifiques. A l’avenir, plus de mesures entre les salles zone 2 et zone 3 seraient
requises pour mieux pouvoir les discerner.
Tests en temps réel (testModels.py)
On lance un scan et on récupère les données en temps réel de RSSI.
On prédit ensuite grâce à nos modèles la zone dans laquelle on se trouve et on l’affiche.
Voici une vidéo dans laquelle on peut le projet implémenté au deuxième étage du bâtiment C à l’UTT. J’ai dû être discret puisque je n’avais aucune idée de si certaines personnes étaient dans ces salles (spoiler : oui).
N’hésitez pas à partager cet article s’il vous a plu, ça me ferait plaisir.
Bon visionnage et bonne journée 🙂
— TM
Laisser un commentaire